
Preparing for Disaster
I was in Manhattan during Hurricane Sandy. The path of the storm was clear, and the outcome largely pre-determined. Because the company I work for (VMsources) has many clients in Manhattan, it was decided that the best place for me, were disaster to strike, was right in Manhattan.
I flew on the last US Airways flight to JFK before the storm, took the last train from Jamaica Station into NYP before the LIRR shut down, and checked into the Hotel Pennsylvania at 34th St. and 8th Ave. This was Sunday night.
On Monday, nothing much happened. The city was shut down, but the rain had not yet started. None of my clients had acted on their DR plan, as services in Manhattan remained substantially unaffected. It was pretty boring though. There were no subways, no LIRR and few cabs. The bridges were still open, but nobody came to work.
On Tuesday, the shit hit the fan. It started raining around noon and poured constantly. The wind came up around 7:00 P.M. and the cops blocked everything south of 32nd street. There were violent explosions beginning around 9:00 P.M. as Con Edison substations became inundated and short circuited. The flashes and explosions were numerous and loud; I could hear them clearly from my 5th floor room.
Miraculously, the mid-town block where the Hotel Pennsylvania is located never lost power. I watched the news until late in the night, as the tunnels all flooded and the bridges were closed. People lost their lives to falling debris in Long Island and Staten Island.
Running DR Plans
Wednesday morning, my cell phone began to ring. All of my Manhattan-based clients were completely offline. Either their VMware vSphere installations were without power, or there was no internet and they could not access their environment. It was DR time!
Some of our clients DR Plan involved replication to private office facilities in Newark and throughout New Jersey. Unfortunately, that proved to be useless as most of the Atlantic Coastline was inundated, from north of Philadelphia to Long Island. Nobody I know, that maintained their own DR site within 100 miles of Manhattan, was able to utilize that facility for days following the storm.
Other clients had replication in place to a colocation or hosting facility (like VMsources) which remained unaffected by Superstorm Sandy. For those clients we helped to enact their Disaster Recovery Plan using Veeam, Zerto and/or VMware Site Recovery Manager.
The first challenge was shutting down the production vSphere clusters. Although not technically required, I felt that this was a prudent measure to prevent a Delta occurring on the production cluster while the client was running at their colocation or DR hosting facility. As it would happen, on Wednesday morning every vSphere Cluster I looked at was powered-on, running on backup building power! I had to wade through water, sometimes up to my knees, to access some of the buildings and gracefully power off vSphere Clusters. This only after “special access” arrangements had been made to allow me into the premises and gain access to the facilities. By midday, I was able to shut-down all of the systems in locations where I could gain physical access.
The next step was running the DR plans. Our clients powered up at their chosen DR facility and were mostly operational in a short period of time. While our team was well-equipped to help organization’s enact their DR plans; clients themselves often forget about the myriad of details over which we have no control, such as:
- Updating DNS with the Registrar
- Alerting service providers like Bloomberg about new IP addresses
- Alerting clients to new VPN Instructions
- and so on.
While initially problematic, these issues would sort themselves out one at a time until every client was able to function successfully from their DR site.
As we continued to support our clients DR efforts, word had gotten out that I was on the ground in NYC, and a number of other organizations contacted us for support with a variety of issues related to the functionality of their DR environments.
Lessons to be learned:
Re-IP does not work!
When you use a VPN or MPLS, one major consideration is that your Recovery site network will be different network from your Production site network. That is to say, if your Production site is on 172.16.0.0/16, then your Recovery site will be on 172.17.0.0/16.
All major Replication and DR products are all capable of changing the IP addresses (Re-IP) of VMs to match the network of the Recovery site, on initiation of a recovery plan. While Re-IP may be a simple expedient, any experienced administrator will tell you that this is a foolish notion! You can’t simply change the IP address of services like SQL or Exchange, much less try to Re-IP an entire Active Directory domain and expect anything to work properly!
During Hurricane Sandy, every situation I encountered with Re-IP’ed VMs, had failed. Sure, the VMs were fully powered up at their DR facility, but nothing was working. It’s quite simple: Neither the forward nor reverse DNS zones of a Re-IP’ed DNS Server was correctly configured. Moreover, everything that mapped directly to an IP address was also broken.
We could have spent hours rebuilding DNS, or we could have un-joined and re-joined every server to the Domain Controller at the DR site, but neither of these fixes guarantees success.
Network Bubble for Disaster Recovery
The solution is remarkably simple in design and execution. For DR plans to function correctly, each VM must be able to power-on at the DR site using its native IP and MAC address, maintaining the same relative relationship to one and other as they have in the production environment. Anything less is a fool’s errand!
Given that the DR site will have a different IP from the Production site, we must create a “Network Bubble” and use a router of some sort to create a dual-NAT relationship so services like Web and Mail will continue to function.
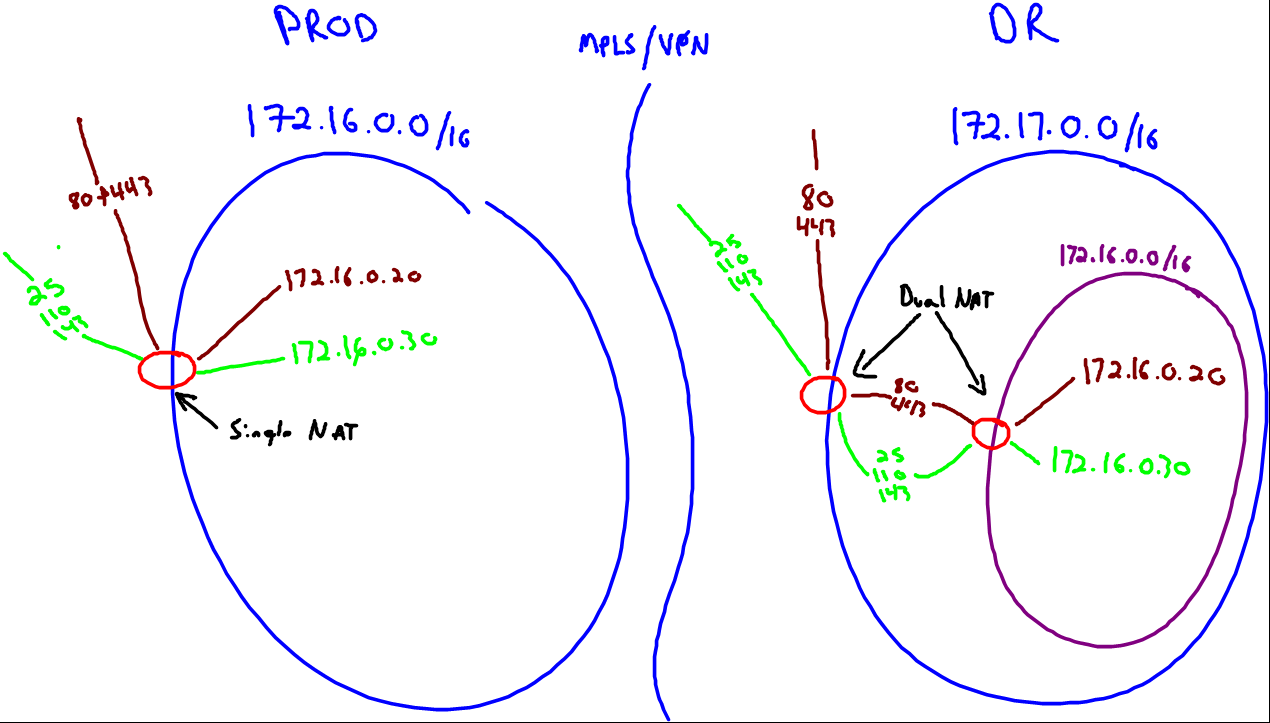
In a normal environment (PROD in the illustration), NAT only has to be applied once: From the internet to whatever server those ports are mapped to. In a DR environment with a Network Bubble, NAT must be applied twice: From the internet to the DR network (172.17.0.0/16 in the illustration) and then from the DR network to the PROD network. Network Bubbles like a charm; we deployed and used them many times during Hurricane Sandy, and helped to save more than a few peoples bacon!