Invalid Snapshot Configuration
Invalid snapshot configurations happen. Mostly, they occur because of problems with storage arrays during snapshot creation/consolidation, but they can also occur if certain process become interrupted (like replication) mid-snapshot.
The more heavily you rely on snapshots, the more likely it is you will come across a problem with snapshots. Specifically if you use a product like Veeam, which leverages a VMware Snapshot to quiesce data, you may see an Invalid Snapshot Configuration from time to time.The more often you protect your data, the more often you create and remove snapshots. This is NOT to sat that there is a problem with Veeam; Veeam is awesome, however it is subject to events on the underlying infrastructure and possible on VPN/MPLS links between sites
For example: A VM with one disk, which is replicated offsite hourly with seven restore points will have the following snapshot overhead:
- 7-9 VMware “snapshots” at the replica site at any given time (these are the restore points)
- Each snapshot is represented by a disk descriptor file “*-0000**.vmdk” and a thin disk representing the delta accumulated “*delta.vmdk”
- 24 VMware snapshots created/removed on the source VM
Fixing Invalid Snapshot Configuration
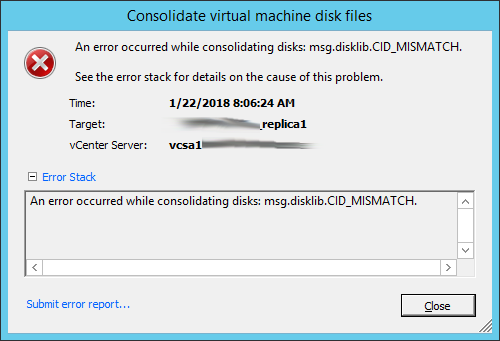
Often when you see an invalid snapshot configuration, VMware is no longer able ro consolidate the disks and you will see the following error:

When this happens, the most effective resolution is to remove the snapshot chain manually, and point the VM back to its original (underlying) *.vmdk and *flat.vmdk file. With Replicas, the priority is on successful replication and each snapshot represents only one restore point. In many cases this is just seven hours worth of replication.
NOTE: This will effectively revert your VM to its state when the first snapshot in the chain was created – this may be many months in some cases!
To manually remove the snapshot chain and revert your VM to its pre-snapshot configuration, you must remove it from your inventory. This can be done by right-clicking on the VM Object in the vSphere Client and selecting “Remove from Inventory.” This does not delete the VM files!
When the VM has been successfully removed, access an ESXi Host using SSH, and browse to the VM folder. Use a command like this:
[root@myhost /] cd /vmfs/volumes/my-datastore-name/my-vm-name
When you get to the folder. list the files and their attributes with the command (NOTE: _replica1 is merely part of my example, could be any suffix, prefix or nothing):
[root@myhost /vmfs/volumes/my-datastore-name/my-vm-name_replica1] ls -lahtr
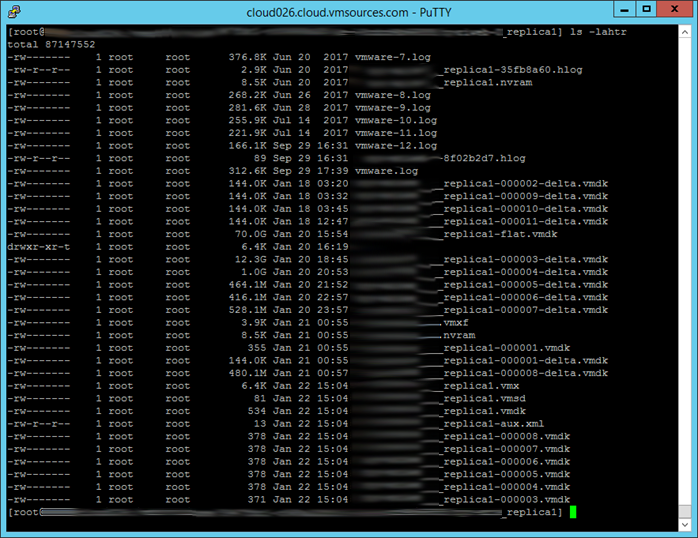
You will see all of the files representing the broken snapshot chain. If you want to know how far you will be rolling back the VM, compare the time/date on *-flat.vmdk with today’s date in UTC. The difference is the life of the snapshot chain.
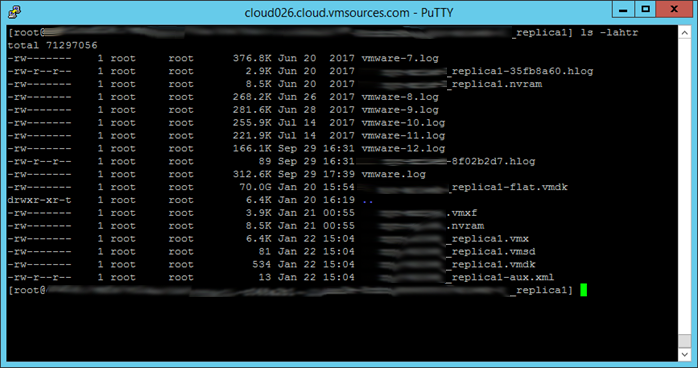
Now you need to get rid of the snapshot chain by running the commands:
[root@myhost /vmfs/volumes/my-datastore-name/my-vm-name_replica1] rm *delta.vmdk
[root@myhost /vmfs/volumes/my-datastore-name/my-vm-name_replica1] rm *0000**.vmdk
Which results in this:
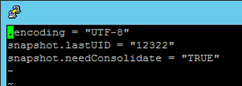
Now you need to edit the snapshot metadata and remove all three lines in the file. I do this with VI, then I use the ‘dd’ command to delete the highlighted liens, then I use the command ‘wq’ to write & quit:
[root@myhost /vmfs/volumes/my-datastore-name/my-vm-name_replica1] vi *.vmsd
Next we need to re-point the *.vmx to the correct disk (not a snapshot) so open the *.vmx for editing:
[root@myhost /vmfs/volumes/my-datastore-name/my-vm-name_replica1] vi *.vmx
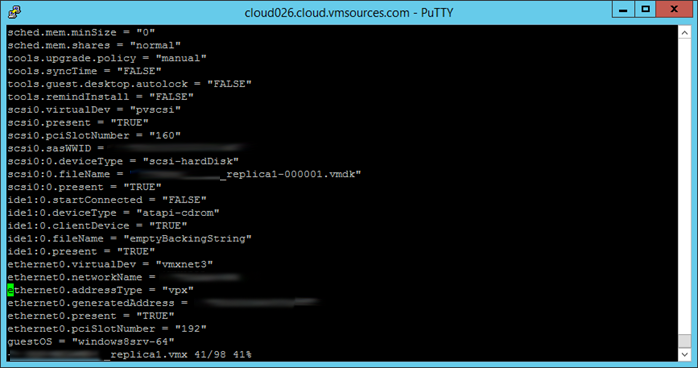
You will notice that the ‘scsi*:*.fileName=’ still points to one of the now deleted disk descriptors for a now-deleted *delta.vmdk. Highlight the line in VI, use the arrow keys to move over the last character of your VM name in the line ‘scsi*:*.fileName=’, and use the delete key to remove the -0000**.vmdk like this:
![]()
Now you are ready to add the VM back to inventory and see how you did!