Timekeeping on ESXi
Timekeeping on ESXi Hosts is a particularly important, yet often overlooked or misunderstood topic among vSphere Administrators.
I recall a recent situation where I created an anti-affinity DRS rule (separate virtual machines) for a customer’s domain controllers. Although ESXi time was correctly configured, the firewall had been recently changed and no longer allowed NTP. As it happened, the entire domain was running fine and time was correct before the anti-affinity rule took effect. Unfortunately, as soon as the DC migrated (based on the rule I created), its time was synchronized with the ESXi host it was moved to, which was approximately 7 minutes slow! The net result was users immediately experienced log-in issues.
Unfortunately, when you configure time on your ESXi Host, there is no affirmative confirmation that the NTP servers you specified are reachable or valid! It doesn’t matter if you add correct NTP servers, or completely bogus addresses to the Time Configuration; the result is that the ESXi will report that the NTP client is running and seemingly in good health! Moreover, there is no warning or alarm when NTP cannot sync with the specified server.
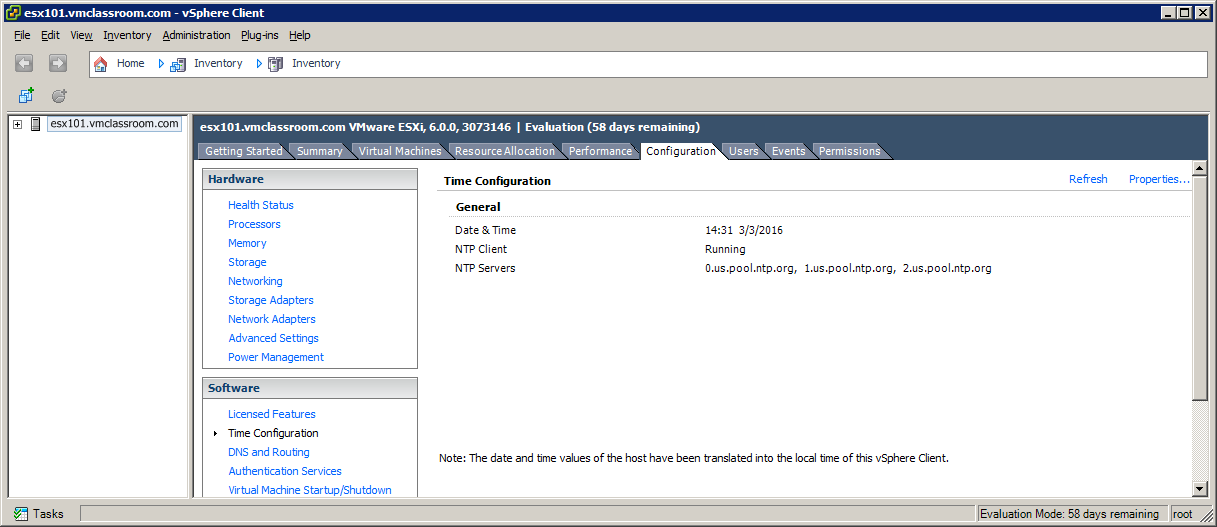
Let’s create an example where we add three bogus NTP servers:
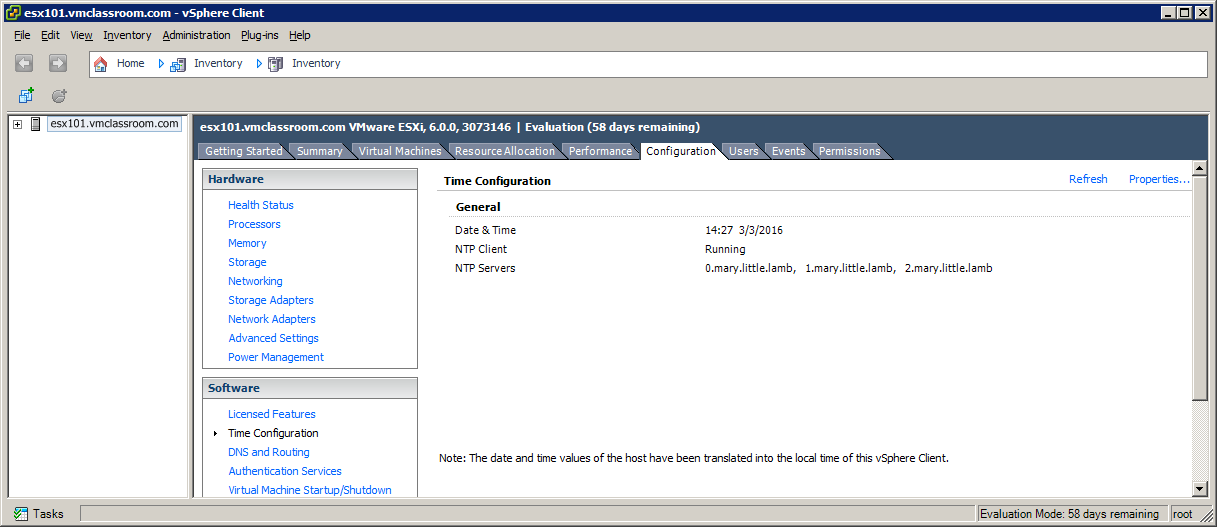
In this example, you can see the three bogus NTP servers, yet the vSphere Client reports that the NTP Client is running and there were no errors!
The only way to tell if your NTP servers are valid and/or functioning is to access the shell of your ESXi host (SSH or Console) and run the command: ntpq –p 127.0.0.1

The result from ntpq –p demonstrates that *.mary.little.lamb is not a NTP server.
Now, let’s try using three valid NTP servers: 
In this example, I have used us.pool.ntp.org to point to three NTP valid servers outside my network and the result (as seen from the vSphere Client) is exactly the same as when we used three bogus servers!

The result from ntpq –p demonstrate that there are three valid NTP servers resolvable by DNS (we used pool.ntp.org), but that the ESXi host has not been able to poll them. This is what you see when the firewall is blocking traffic on port 123!
Additionally, when firewall rules change, preventing access to NTP, the ‘when’ column will show a value (sometimes in days!) much larger than the poll interval!
When an ESXi host is correctly configured with valid NTP servers and it is actually getting time from those servers, the result form ntpq –p will look like this:
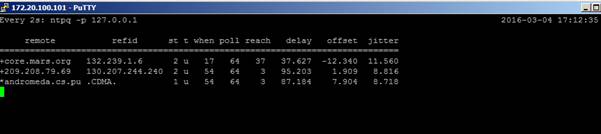
Here you see the following values:
| remote | Hostname or IP of the NTP server this ESXi host is actually using, |
| rfid | Identification of the time stream.
|
| st | Stratum |
| t | tcp or udp |
| when | last time (in seconds) the NTP was successfully queried. This is the important value: when the ‘when’ value is larger than the “poll” field, NTP is not working! |
| poll | poll interval (in seconds) |
| reach | An 8-bit shift register in octal (base 8), with each bit representing success (1) or failure (0) in contacting the configured NTP server. A value of 377 is ideal, representing success in the last 8 attempts to query the NTP server. |
| delay | Round trip (in milliseconds) to the NTP Server |
| offset | Difference (in milliseconds) in the actual time on the ESXi host and the reported time from the NTP server. |
| jitter | the observed variance in the observed response from the NTP server. Lower values are better. |
The NIST publishes a list of valid NTP IP addresses and Hostnames, but I prefer to use pool.ntp.org in all situations where the ESXi Host can be permitted access to a NTP server on port 123. The advantage to pool.ntp.org is that it changes dynamically with availability and usability of NTP servers. Theoretically, pool.ntp.org is a set-and-forget kind of thing!
ESXi Time Best Practices
Do not use a VM (such as a Domain Controller) that could potentially be hosted by this ESXi as a time-source.
Use only Stratum 1 or Stratum 2 NTP Servers
Verify NTP Functionality with: ntpq –p 127.0.0.1
VMs which are already timeservers (such as Domain Controllers) should use either native time services such as w32time or VMware Tools time synchronization, not both! See: VMware KB 1318