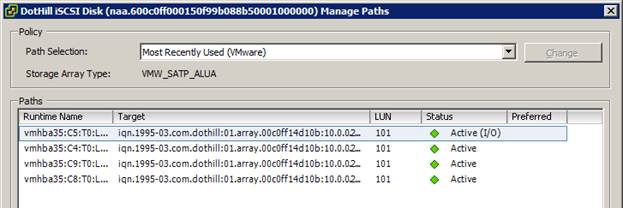
Updating Photon OS with yum
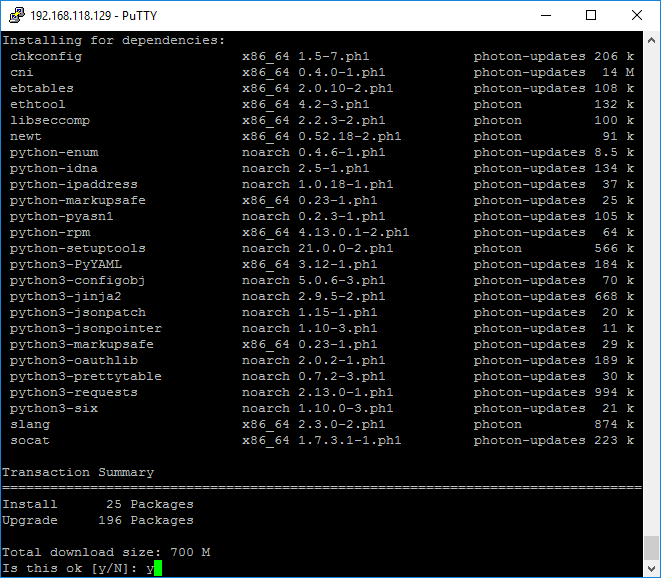
VMware photon OS is described as “yum compatible.” Yum has been the package manager for all Fedora derivative distros like RHEL and CentOS. Photon OS actually uses Tiny DNF (TDNF), which appears to be a fork of the Fedora DNF package management system.